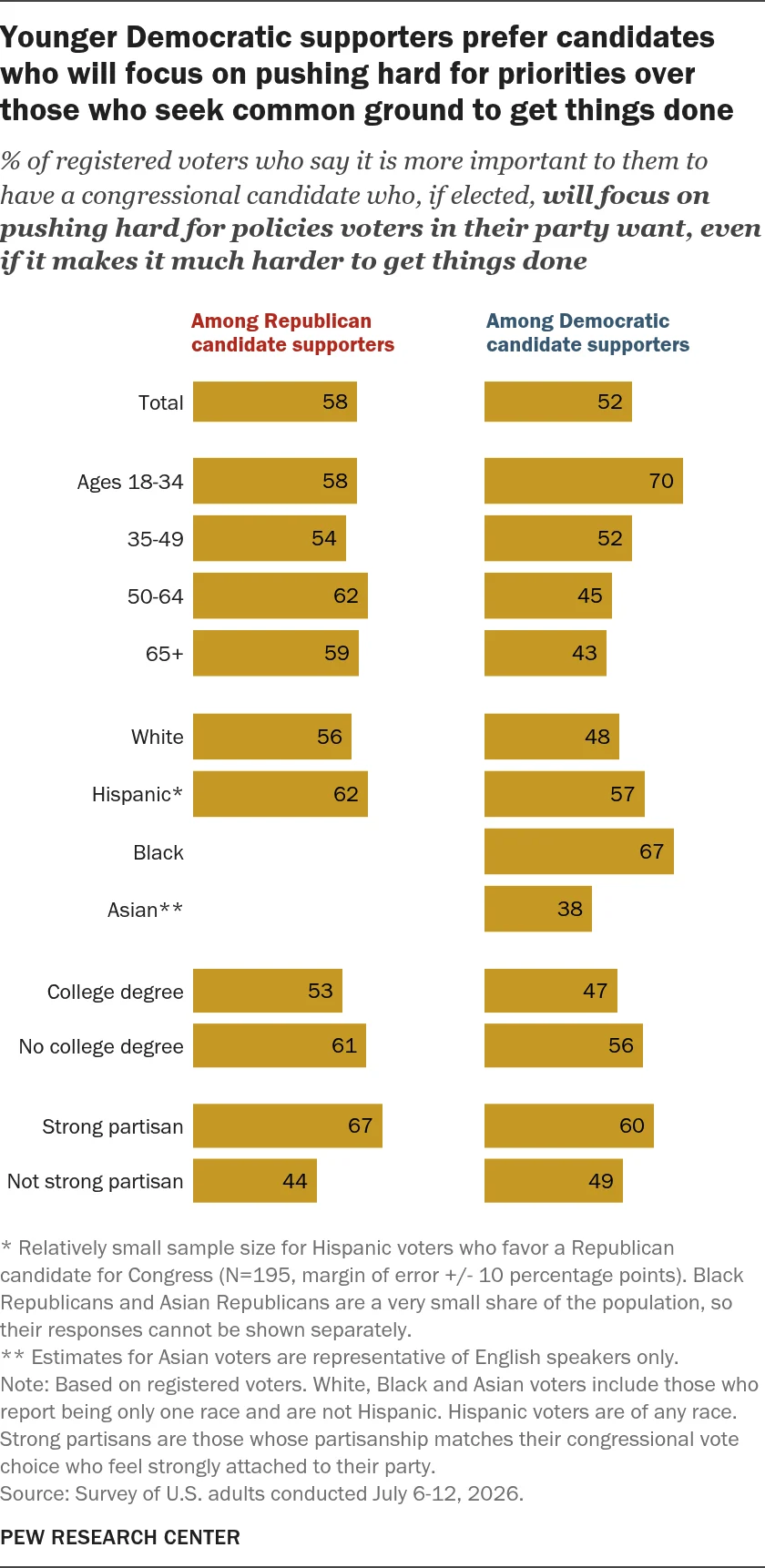
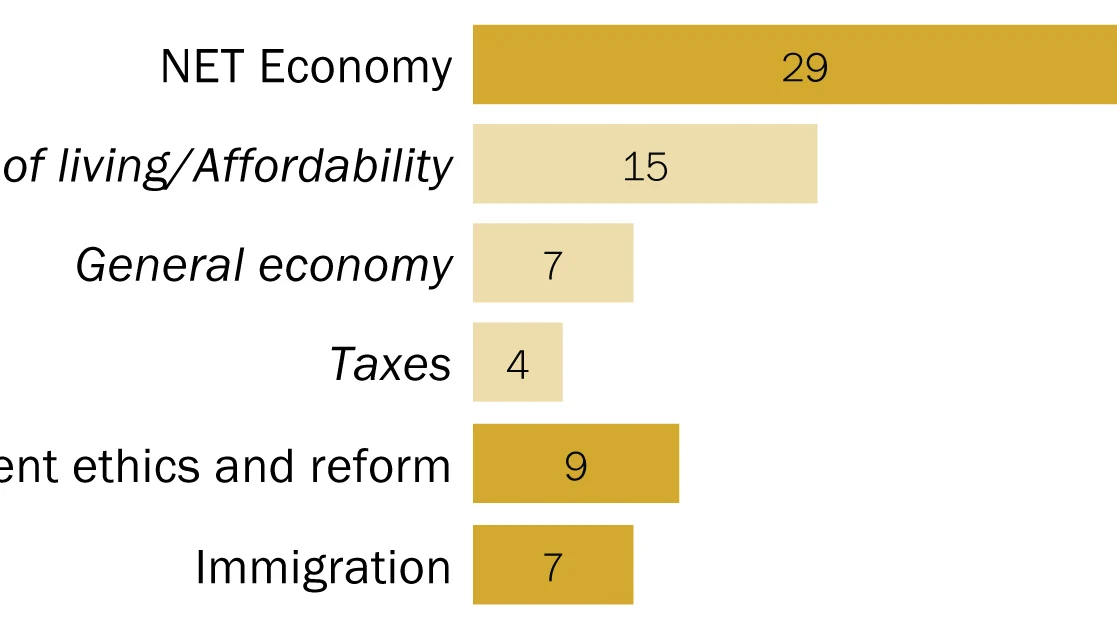
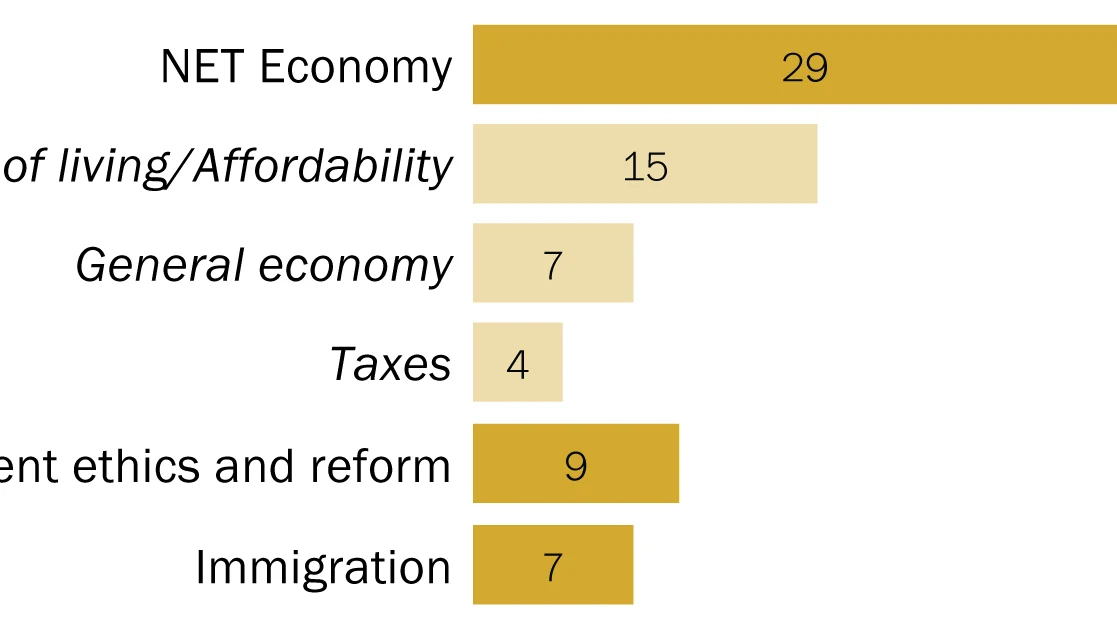
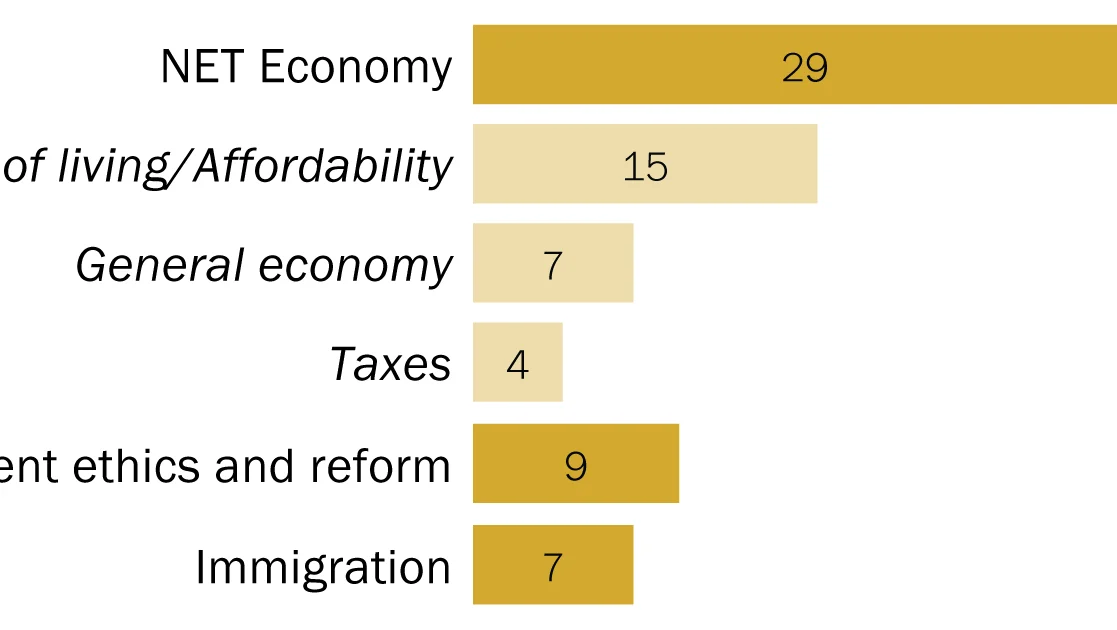
This comprehensive report details the rigorous methodologies employed by the Pew Research Center, in collaboration with the John S. and James L. Knight Foundation, to conduct its extensive research on religious radio in the United States. The study leverages multiple data sources, including a large-scale national survey, detailed analysis of station websites, and extensive recording and transcription of internet broadcasts. These methods were meticulously designed to ensure the accuracy, representativeness, and depth of the findings presented.
The American Trends Panel: A Cornerstone of Pew Research
The foundation of this report’s survey data lies in Wave 173 of the American Trends Panel (ATP). This nationally representative panel comprises randomly selected U.S. adults, offering a robust sample for gauging public opinion and experiences. The survey was conducted between June 9th and June 15th, 2025, with an impressive 88% response rate from the 5,737 individuals sampled, resulting in 5,023 completed surveys. While the survey-level response rate was high, the cumulative response rate, accounting for initial recruitment and ongoing panel attrition, stands at 3%. The break-off rate among participants who began the survey was minimal, at just 1%, indicating a high level of engagement. The margin of sampling error for the full sample is a narrow ±1.6 percentage points, underscoring the precision of the data.

To ensure adequate representation of smaller demographic groups, the study incorporated an oversample of non-Hispanic Asian adults. This technique is crucial for providing more reliable estimates of the opinions and experiences of these communities, with oversampled groups being statistically weighted back to their accurate proportion within the U.S. population. The survey was administered by SSRS, utilizing both online (4,842 respondents) and live telephone (181 respondents) interviews, conducted in English and Spanish to maximize accessibility.
Panel Recruitment and Design
Since 2018, the ATP has employed an address-based sampling (ABS) method for recruitment. This process involves mailing study materials and an initial incentive to a stratified, random sample of households selected from the U.S. Postal Service’s Computerized Delivery Sequence File, which covers an estimated 90% to 98% of the U.S. population. Within each selected household, the adult with the next birthday is invited to participate. Prior to 2018, the ATP relied on random-digit-dial surveys for recruitment. Annual recruitment efforts have included oversamples for underrepresented groups, such as Hispanic, Black, and Asian adults in specific years, to enhance data accuracy for these demographics.
The sample design for this specific survey targeted noninstitutionalized U.S. adults aged 18 and older. It utilized a stratified random sample from the ATP, with non-Hispanic Asian adults selected with certainty. The remaining panelists were sampled to maintain proportionality with the U.S. adult population across different strata. Respondent weights were adjusted to reflect differential probabilities of selection.
Questionnaire Development and Data Collection
The questionnaire was meticulously developed by Pew Research Center in consultation with SSRS. Rigorous testing was conducted on both PC and mobile devices by the SSRS project team and Pew Research Center researchers to ensure the web program’s functionality. Test data was analyzed to verify survey logic and randomizations before launch.
Respondents were offered post-paid incentives, with options for checks or gift codes for major online retailers, ranging from $5 to $20 based on the ease of reaching specific demographic groups. This differential incentive strategy aims to boost participation among historically harder-to-reach populations.
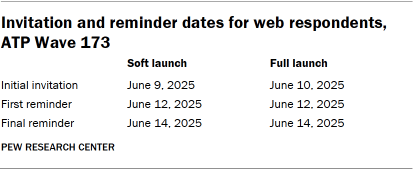
The data collection field period for this survey ran from June 9th to June 15th, 2025. Online survey participants received email invitations and up to two reminders. Panelists who consented to SMS messaging received invitations and reminders via text. For telephone interviews, prenotification postcards were mailed on June 6th, followed by a soft launch on June 9th to secure initial interviews. Remaining sampled phone panelists received up to six calls from trained SSRS interviewers.
Data Quality and Weighting
To ensure data integrity, Pew Research Center researchers conducted thorough data quality checks to identify any respondents exhibiting patterns of satisficing, such as excessively high rates of unanswered questions or consistent selection of the first or last answer option. Three respondents were excluded from the final dataset based on these checks.
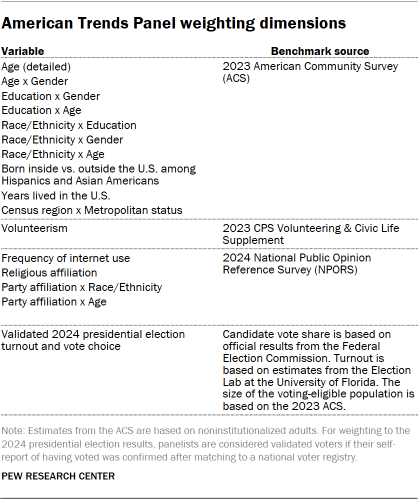
The ATP data undergoes a comprehensive weighting process to account for multiple stages of sampling and nonresponse. Each panelist receives a base weight reflecting their recruitment probability. These weights are then calibrated to population benchmarks to correct for nonresponse to recruitment surveys and panel attrition. If a subsample was invited for a specific wave, weights are adjusted for differential selection probabilities. Finally, weights are recalibrated to population benchmarks and trimmed at the 1st and 99th percentiles to minimize variance. Sampling errors and statistical significance tests account for the weighting effect.
Identifying the Landscape of Religious Radio
A crucial aspect of this research involved systematically identifying the population of religious radio stations operating across the United States. This was primarily achieved by utilizing data from Radio-Locator, a specialized vendor maintaining up-to-date administrative information on U.S. and international radio stations. Their database, drawing from FCC licensing information, provides details on station location, call sign, band, frequency, and licensee. This data is further enriched with genre, website URLs, live audio stream URLs, and coverage area information. A snapshot of the Radio-Locator database from March 2025 was used for this analysis.

The Radio-Locator database encompasses 25,753 stations in the 50 U.S. states and the District of Columbia. This includes 17,115 primary AM or FM stations and 8,638 secondary booster or translator stations. While booster and translator stations were included in geographic coverage estimates, the main analysis focused on primary stations.
Defining and Categorizing Religious Content
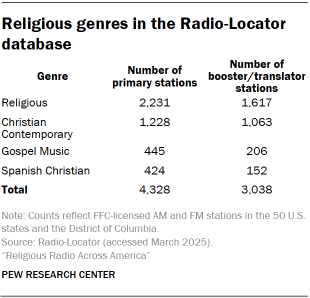
Each station in the Radio-Locator database is assigned a primary genre label. For this study, stations were classified as "religious" if their content fell under the categories of Religious, Christian Contemporary, Gospel Music, or Spanish Christian. This yielded a total of 7,366 religious stations in the database, with 4,328 identified as primary stations for the core analysis. While Spanish Christian stations were included in administrative data analyses, they were excluded from the live radio content analysis.
The vast majority of religious radio programming in the U.S. is Christian. The study identified only two stations clearly affiliated with other religious traditions: a low-power FM station in Lakewood, New Jersey, operated by a Jewish organization (WMDI-LP), and an AM station in Spanish Fork, Utah, operated by a Hare Krishna temple (KHQN). Religious content on public, talk, or community radio stations, when not their primary genre, was not included in this analysis.

Station Website Analysis
Researchers examined the websites of 3,332 stations (85% of those included) to gather information about the station, its affiliated religious tradition or denomination, and any "About us" statements. Additionally, the broadcast schedules of a randomly selected sample of 300 stations with both a website and an audio stream URL were coded. This involved analyzing 24-hour broadcast schedules in 15-minute blocks, recording program names, host information, program type (talk or music), and start/end times. Seven days of scheduling information were collected for each sampled station, with a preference for July 2025 schedules, or April-May 2025 if the former was unavailable. This process allowed for the estimation of shows appearing on the largest number of stations.
Capturing the Soundscape: Recording and Transcribing Internet Broadcasts
To gain a granular understanding of religious radio content, the research team undertook a large-scale effort to record, transcribe, and analyze internet radio streams from 2,083 religious radio stations broadcasting primarily in English and streaming online. Due to the common practice of multiple stations sharing a single live broadcast stream, this set of stations was represented by 785 unique web stream URLs.
Strategic Sampling of Broadcasts
With a computational capacity to monitor 250 audio streams simultaneously, the study adopted a strategy of recording in 15-minute time blocks uniformly distributed across all available web streams. This "record all stations some of the time" approach contrasted with "record some stations all the time." The data collection window spanned the entire month of July 2025. A total of 250 recording blocks were scheduled every 15 minutes, 24 hours a day, accumulating to 744,000 recordings over the 31 days. To maximize coverage, instances where multiple stations shared a URL were treated as a single entry in the sampling frame, with recordings assigned to all stations sharing that URL. On average, each station’s web stream was allocated approximately 237 hours of dedicated recording time.

A Note on Educational Media Foundation Stations
It is important to note that the Educational Media Foundation (EMF), the largest owner of religious radio stations in the U.S. through its Air1 and K-LOVE networks, was excluded from the recorded content analysis. These networks, primarily featuring Christian music, deliver their content via proprietary web players and mobile applications that do not provide publicly accessible stream URLs compatible with the automated recording system. While EMF stations are included in administrative data analyses like station counts and geographic coverage, their audio content could not be consistently captured by the automated infrastructure.
Recording Infrastructure and Data Volume
The recording process relied on a cluster of 250 containerized stream listener applications. Each listener, operating on a predefined schedule, connected to its assigned URL and processed audio using the FFmpeg framework. After each 15-minute slot, the audio was saved as a low-bit rate (64 kbps) MP3 file. This system successfully captured 716,626 15-minute recordings, representing 96% of scheduled time slots. This equates to roughly 230 hours of audio per unique web stream URL, totaling nearly 440,000 hours of audio when accounting for shared streams.
Speech-to-Text Transcription
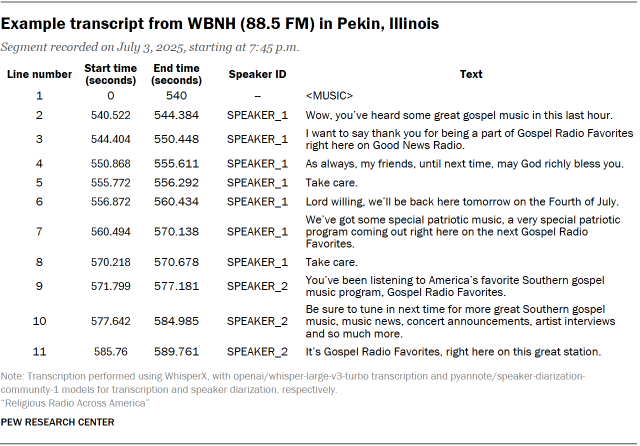
The recorded audio files were then processed through a machine transcription pipeline utilizing the WhisperX system. This system extends basic speech-to-text capabilities with speaker differentiation (diarization) and time-stamp alignment. The implemented pipeline produced line-level transcripts, breaking down spoken content into individual "utterances" tagged with speaker IDs and precise time stamps. This process generated over 186 million lines of dialogue for analysis.
Decoding Spoken Content: Segmentation and Classification
The transcribed audio data was subjected to sophisticated analysis to categorize spoken content. Each approximately 15-minute transcript was processed by a large language model (GPT-4.1) to segment it into coherent topical units, moving beyond fixed time intervals. This segmentation considered speaker turns and lexical continuity to identify boundaries where subject matter, interactional format, or program structure shifted.
Identifying Radio Segment Formats
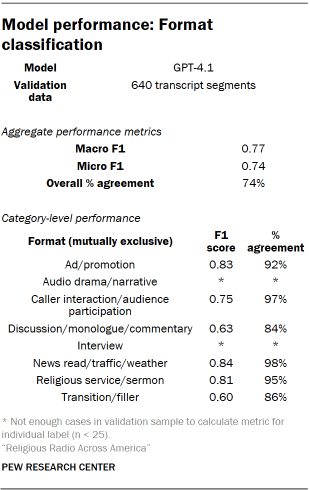
The first layer of classification focused on segment "format," identifying the basic type of programming containing speech. Researchers developed a codebook of expected formats, including talk programming, news reads, sermons, audience participation, and advertisements. An iterative human coding process refined these categories, leading to a finalized list of mutually exclusive formats. This codebook was then integrated into the processing pipeline for GPT-4.1 classification. Validation of this task involved hand-coding by three researchers, with disagreements resolved using a Dawid-Skene aggregation model.
Named Entity Recognition (NER)
Named entity recognition (NER) was employed to identify and classify real-world entities within the transcripts, such as people, groups, and places. NER was also used to flag titles of stories, books (including religious scriptures), and references to specific scriptural passages. The NER model was instructed to identify entities and their types. Validation involved three researchers independently coding a sample of identified entities and their predicted types, with disagreements resolved through the Dawid-Skene model.
Broad Topic and Subtopic Classification
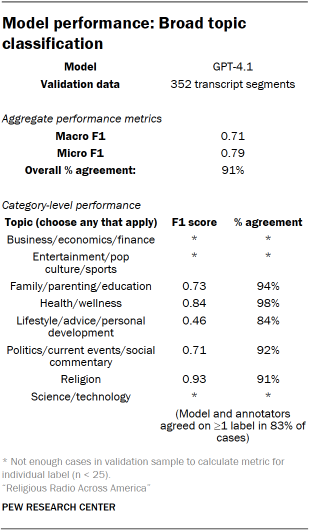
Segments were further categorized by "topics" discussed. This classification aimed to broadly capture the thematic areas of religious talk radio. Topics were not mutually exclusive, allowing segments to be labeled with multiple applicable areas. An iterative human coding process defined the final list of broad topics, which included Religion, Politics/current events/social commentary, Health/wellness, Business/economy/finance, and Science/technology.
For segments with specific topic labels, a subtopic model was applied to identify more granular areas of discussion. This classification also allowed for multiple subtopic labels per segment. The subtopic model was fine-tuned on a set of synthetic labels generated by GPT-4.1. Validation was conducted through hand-coding by three researchers.
Classifying Issue Stance
Beyond topic identification, the research aimed to assess speakers’ attitudes toward key issues. A "stance" classification system was developed to determine if a text was neutral or opinionated, and if opinionated, whether the sentiment was favorable or unfavorable. Stance was coded for a selection of issues, individuals, and groups drawn from NER and subtopic classification. For most issues, segments were coded as neutral or opinionated, with opinionated texts further classified as favorable/unfavorable. The crime/law enforcement and economy subtopics were only coded as neutral or opinionated due to their less clear directional stances.
The full set of issues, individuals, and groups analyzed for stance included a comprehensive list covering religious figures, political leaders, policy areas, and social issues. This classification was also performed using a fine-tuned ModernBERT model, with validation through hand-coding and the Dawid-Skene aggregation model.
Speaker Gender Prediction
To estimate speaker gender, a pretrained wav2vec2 model, fine-tuned for age and gender prediction, was utilized. This model analyzes vocal characteristics to predict gender. Given the time-stamped transcripts with speaker labels, individual utterances were extracted, passed to the model, and the predictions were aggregated at the speaker level. This probabilistic approach, based solely on acoustic features, provides a binary male/female classification. Validation of this model showed a 98% agreement rate with human judgment on a sample of utterances.
Uncovering Musical Content
A distinct methodology was applied to differentiate and identify musical content within the recorded broadcasts.

Differentiating Music from Speech
An Audio Spectrogram Transformer (AST) model, MIT/ast-finetuned-audioset-10-10-0.4593, was employed to distinguish between music and speech. The 15-minute recordings were chunked into overlapping 10-second segments for classification. Segments classified as both speech and music were designated as speech. Segments identified as music were marked with "" in the transcript, irrespective of any attempted lyric transcription.
Identifying Tracks, Artists, and Genres
To identify specific musical tracks, artists, and genres, the AudD music recognition API was utilized. A random sample of 249,076 15-minute recordings was analyzed, selecting a 12-second music clip from recordings with at least two minutes of continuous music. This process identified 131,825 recordings with identifiable music, resulting in 39,262 distinct tracks by 13,594 artists.
Approximately 93% of identified tracks had associated metadata in the Spotify music library, allowing for retrieval of more detailed artist information, including genres. Researchers reviewed the top 25 most common genre tags and consolidated them into standardized categories for analysis, providing a structured overview of the musical landscape on religious radio.
Mapping Programming onto a 24-Hour Schedule
The content analysis is based on approximately 440,000 hours of recorded audio. While the recordings were made in 15-minute blocks, the reporting of findings in "hours per day" is derived from the proportion of content categories observed. For instance, if half of the recorded material for a station is music, it is estimated to broadcast 12 hours of music per day on average. This calculation assumes continuous 24-hour broadcasting, which was found to be the case for the vast majority of religious stations via their web streams. Validation checks for dead air found minimal silence, with no statistically significant difference between overnight and daytime broadcasting. This robust methodological framework ensures that the findings regarding religious radio programming are based on comprehensive and rigorously analyzed data.